![]()
Open Source
![]()
Field Reconfigurable
![]()
Free AI Framework
![]()
High Performance and Low Power
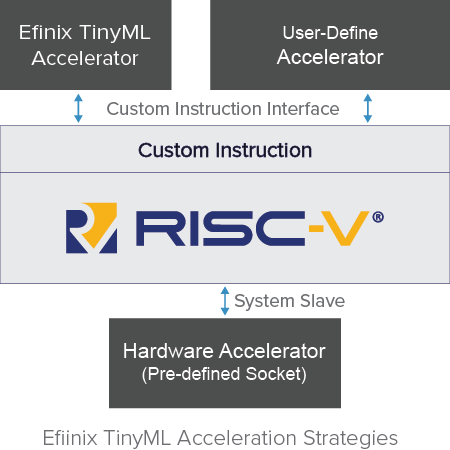
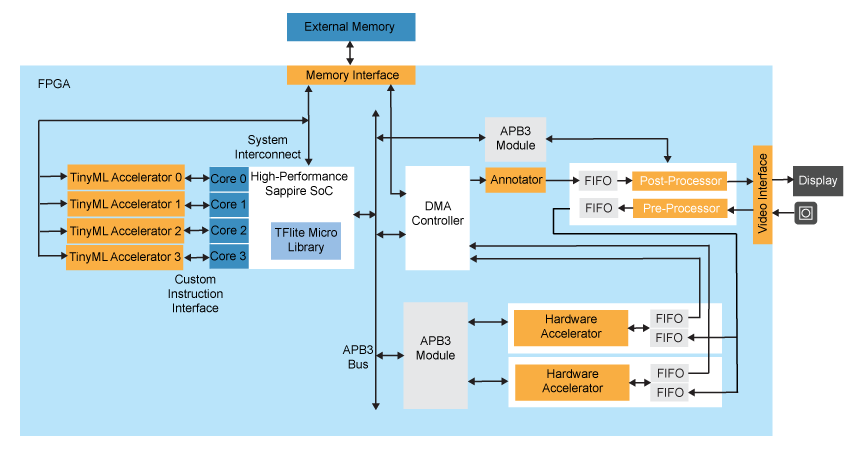
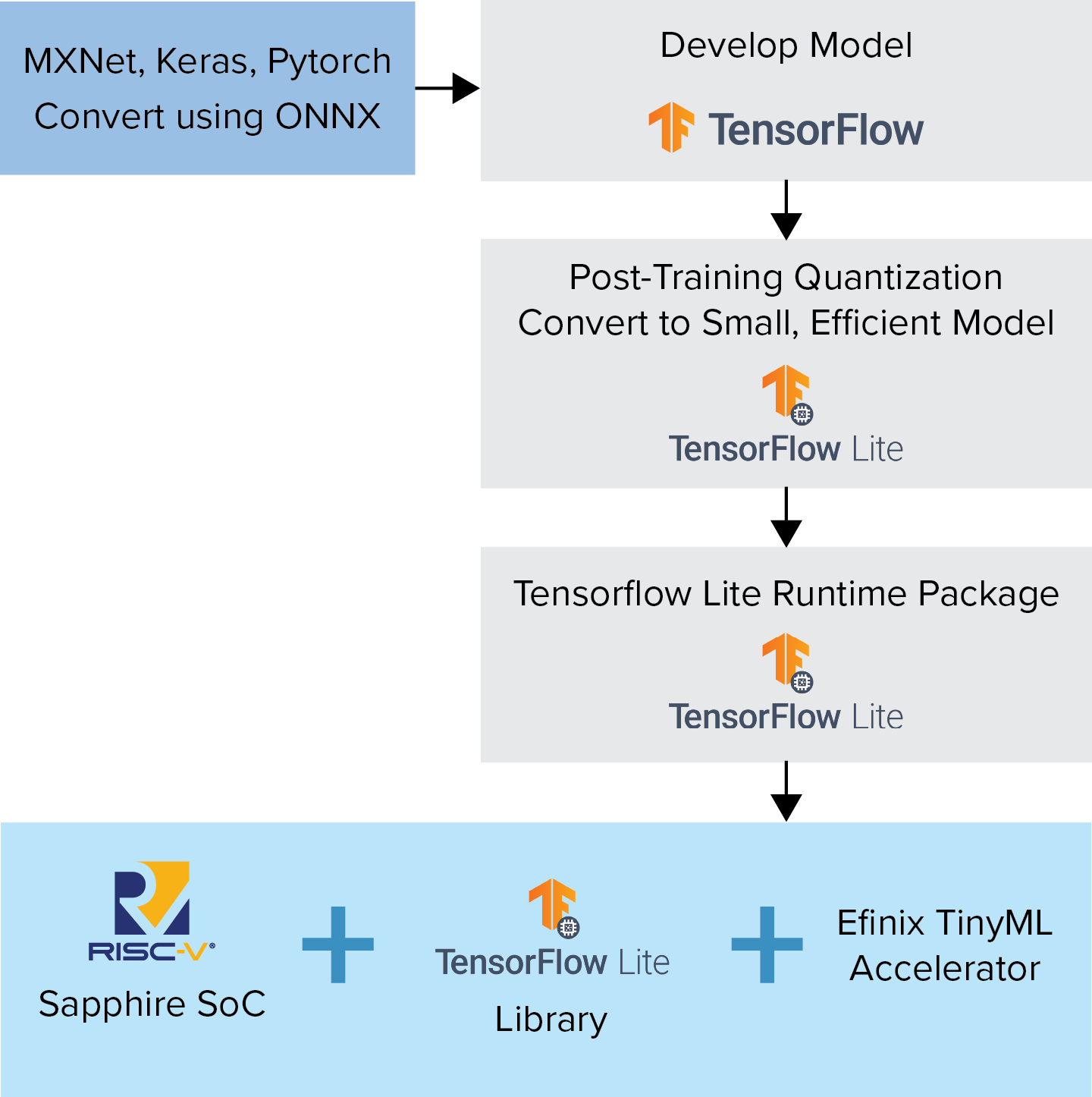
There is a drive to push Artificial Intelligence (AI) closer to the network edge where it can operate on data with lower latency and increased context. Power and compute resources are at a premium at the edge however and compute hungry AI algorithms find it hard to deliver the performance required. The open source community has developed TensorFlow lite that creates a quantized version of standard TensorFlow models and, using a library of functions, enables them to run on microcontrollers at the far edge. The Efinix TinyML platform takes these TensorFlow Lite models and, using the custom instruction capabilities of the Sapphire core, accelerates them in the FPGA hardware to dramatically improve their performance while retaining a low power and small footprint .
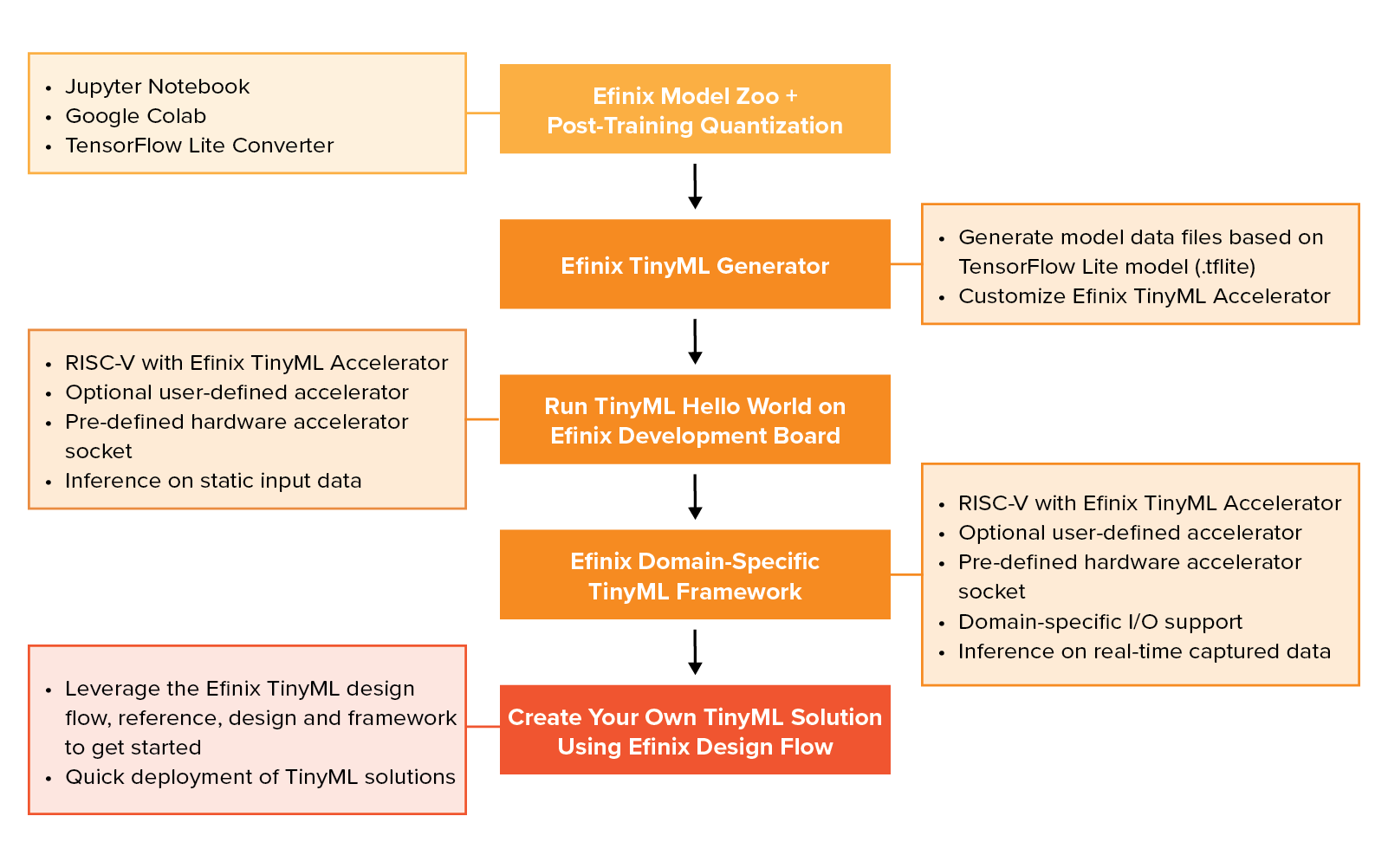
Advantages of Efinix TinyML Platform
- Flexible AI solutions with configurable Sapphire SoC suite, Efinix TinyML Accelerator, optional user-defined accelerator, hardware accelerator socket to cater for various applications needs.
- Support all AI inferences that are supported by the TFLite Micro library, which is maintained by open-source community.
- Multiple acceleration options with different performance-and-design-effort ratio to speed-up overall AI inference deployment.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.